Why Dask?
Over the last quarter of 2021, the Alpha squad at Perpetua worked relentlessly to productionize a computationally expensive algorithm. The algorithm ingests millions of rows with unstructured text data and builds a statistical model before proceeding to the inference stage. One of the bottlenecks in deploying the feature was its inability to scale for TBs worth of data. It was evident that we needed a scalable framework to make it work !!

We could have addressed this issue in a few different ways (MapReduce, Spark, etc) but we decided to go with Dask for a couple of reasons:
- Dask uses existing python APIs and data structures. This resulted in a much faster development cycle.
- Dask integrates seamlessly with GCP services including BigQuery, Vertex AI, and Dataproc.
The goal of this article is to highlight the prominent learnings/caveats that we unearthed while working with Dask. So, with much further ado, here we go:
1. groupby() vs map_partitions(groupby()):
- Aggregating data by groups is one of the most common use-cases in the analytics world.
- Grouping and Aggregating data using Dask can be as simple as using
.groupby()on the Dask dataframe. - However, it is important to note that by using just
.groupby(), the reduced dataframe is returned with one partition. - If you expect the reduced dataframe to be large, it is recommended to use
.groupby()with.map_partition()

2. Importance of setting index:
- Consider a scenario as before where you would want to groupby and aggregate a Dask dataframe using map_partitions.
- Let us see the implication of NOT setting the index.
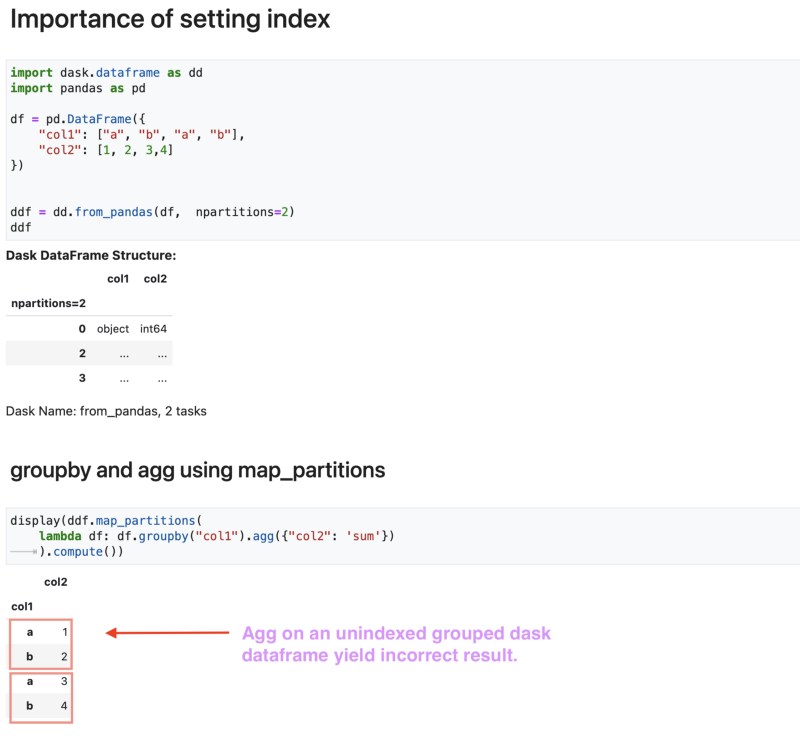
- It can be clearly seen that the aggregation on an unindexed grouped dataframe results in incorrect output.
- To fix this issue, we need to explicitly set the index of the dataframe.
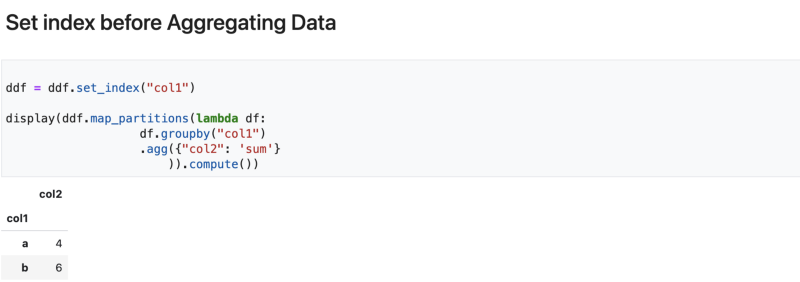
- It is important to note that, setting an index on a dataframe is an expensive operation and should be used sparingly.
- Additionally, as of Dec 2021, Dask does NOT support setting indices on multiple columns.
3. Importance of Persisting a Dataframe:
- Dask objects (dataframes, arrays, bags) are stored on disk. All the operations on the Dask objects involve reading the data from the disk before performing the operation.
- However, reading data from RAM is typically faster than reading it from the disk.
- To facilitate faster computation, Dask allows loading objects in the RAM instead of loading them from disk every single time.
- This is done using the
.persist()method on the Dask object. -
However, persisting Dask objects yields richer dividends for situations when:
- A large dataset is filtered and is expected to fit in memory.
- There are multiple subsequent operations to be performed on the filtered dataset.
- Let us take a look at a quick example. We start off with a large dataset. The goal is to filter the large dataset by some value and perform certain exploratory and arithmetic operations on the filtered dataset.

- It can be seen from the above screenshot that by persisting the filtered dataframe, the run time reduces by more than 50% from 104s to 48s.
4. Importance of Repartitioning:
- We know that a Dask object is stored on the disk using partitions.
- Various operations can then be applied to these partitions to get the desired outcome.
- The number of partitions can have a direct impact on the run time.
- Decreasing the number of partitions may result in Memory issues whereas increasing the number of partitions may add significant computational overhead thereby leading to longer run times.
- Dask determines the optimal number of partitions while reading data from the source (eg: parquet files).
- Dask’s Best Practices Documentation for dataframes recommends a partition size of 100MB.
- There are instances where you would want to repartition a dataframe, for eg, after filtering data.
- If filtering a Dask dataframe is expected to result in a significantly smaller dataset, it is recommended to repartition the dataframe.
- To demonstrate the value, let us consider a simple example where we filter the dataframe and compute the number of unique values in a column.
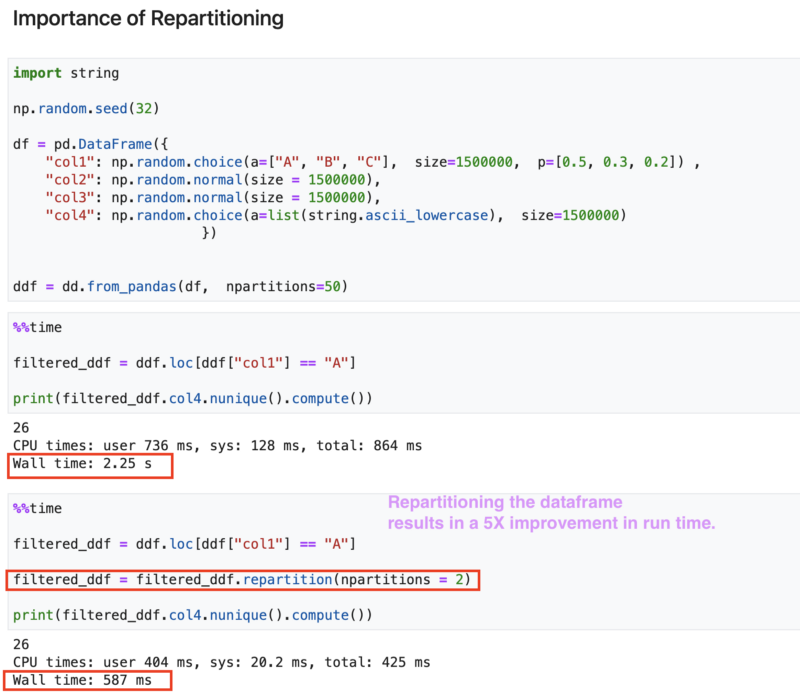
- For our toy example, repartitioning the dataframe resulted in a 5X improvement in run time.
5. Vectorize, Vectorize, Vectorize:
- Finally, I would like to highlight the fact that while distributed computing frameworks like DASK can help scale algorithms, it is NOT the silver bullet.
- No free lunch theory: Distributed computing comes with significant overhead costs. Before procuring Dask clusters, it is probably worth attempting to optimize the code in native python.
- To prove my point, consider a simple operation of multiplying two columns of a dataframe.
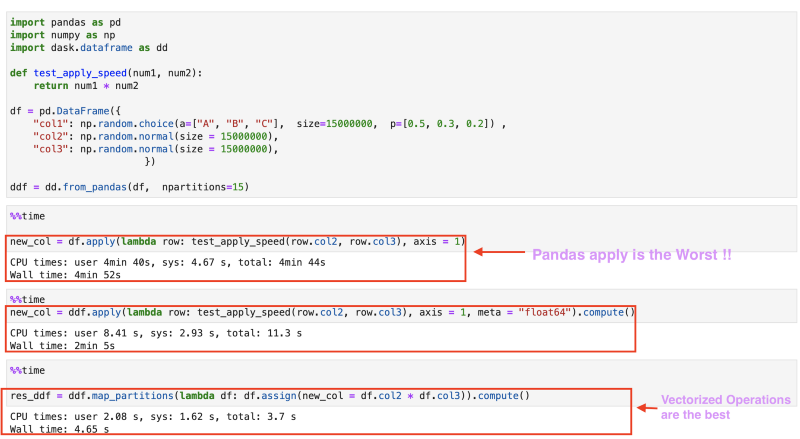
- From the above screenshot, it can be seen that applying a function along a row of the pandas dataframe is the slowest.
- Distributing the apply function using Dask dataframe reduces the run times by half.
- However, the biggest drop in run time comes from using distributed computing using vectorized operations. Vectorized Operations are a whopping 30x faster.
Let’s have a chat:
- We, at Perpetua are on a mission to give superpowers to anyone who sells online.
- If you made it till this section of the blog and are passionate about solving complex problems in the advertising space, get in touch with us and be a part of our amazing journey.
- Feel free to check out our current openings. If you don’t see an opening in the field of your preference, surprise us by telling how you would like to contribute.
🌱 Come grow with us!
- Engineering Manager (m/f/d) - Remote possible
- Senior Data Engineer (m/f/d) - Remote possible
- Principal Front End Engineer
- Senior Data Scientist (m/f/d) - (EU) Remote friendly
- Senior Software Development Engineer In Test (Javascript)
- Senior Software Engineer - Frontend
- Software Engineer - Backend
- Senior Software Engineer - Backend